
 Table of Contents
Table of Contents  Previous Section
Previous Section
Figure 47. What Happens During a Fetch
Note: Figure 47 is intended to show the flow of data, not the Enterprise Objects Framework architecture as such. For a graphical depiction of the Enterprise Objects Framework architecture, see the chapter "What Is Enterprise Objects Framework?"
The steps illustrated in Figure 47 are described in detail in the following sections.
When a display group receives a fetch message, the following sequence of events occurs:
The database data source would already have a fetch specification if you assigned one programmatically or if you assigned one in Interface Builder (or WebObjects Builder in a WebObjects application). Fetch specifications are handled differently depending on how they're configured. This discussion assumes that the fetch specification is a "regular" fetch specification-one that isn't configured to fetch raw rows, to use a custom SQL statement, or to use a stored procedure.
To do this it uses an EODatabaseChannel, whose job is specifically to fetch enterprise objects. The database channel in turn uses an EOAdaptorChannel for low-level communication with the database, along with whatever model objects-EOEntities, EOAttributes, and EORelationships-are needed to perform the fetch.
Fetching objects happens in two major steps:
With respect to locking, note that in addition to setting an overall locking strategy, you can take advantage of EODatabaseContext's "on demand" locking feature to lock individual rows. For more information, see "Locking and Update Strategies".
An EODatabaseContext also posts notifications that your objects can receive and react to.
If the fetch specification is set to refresh refetched objects, an ObjectsChangedInStoreNotification (EOObjectsChangedInStoreNotification in Objective-C) is posted to invalidate (refault) any existing instances corresponding to this globalID.
The createInstanceWithEditingContext method provides the enterprise object class's constructor with an editing context, the entity class description, and a globalID. You'll rarely need to use this information at this point, but you might choose to if, for example, you need to extract the primary key from the globalID to do some processing on it.
Your custom enterprise object classes can also implement the method awakeFromInsertion (awakeFromInsertionInEditingContext: in Objective-C), which is invoked immediately after your application creates a new object and inserts it into an EOEditingContext. This method lets you assign values to newly created enterprise objects. For more discussion of this topic, see the chapter "Designing Enterprise Objects".
Figure 48 shows how a new object gets instantiated with database data. The scenario it depicts is fetching a single, new object from the database.
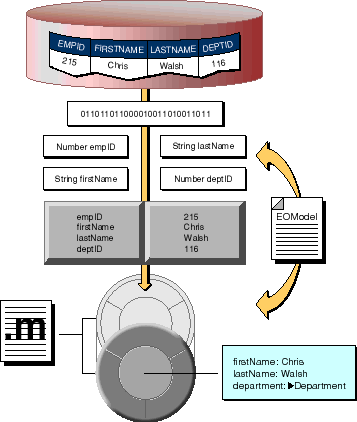
Figure 48. Flow of Data During a Fetch
This process is described in greater detail below.
The following sequence of events occurs when an object is fetched from the database:
NULL values in the database are mapped to instances of EONullValue (EONull in Objective-C).
Additionally, you can map external data types to custom value classes defined by your application. For more discussion of this subject, see the chapter "Advanced Enterprise Object Modeling".
The dictionary provides a snapshot of the database row, and it's later used to initialize the enterprise object. The snapshot also comes into play when changes to the object are saved to the database; for more discussion of this topic see the section "Snapshots".
When an enterprise object is initialized, EONullValue objects (or EONull objects in Objective-C) are passed to the object as null (nil in Objective-C) so you don't have to write code to handle NULLs.
Enterprise Objects Framework maintains the mapping of each enterprise object to its corresponding database row, and uses this information to ensure that your object graph does not have two (possibly inconsistent) objects for the same database row.
When objects are fetched, Enterprise Objects Framework records the state of the corresponding database row. This information is used when changes are saved back out to the database to ensure that the row data has not been changed by someone else since it was last fetched. The information is also used to only update attributes that have changed, rather than all of them.
The objects at the destination of a fetched object's relationships are only fetched on demand; however, these objects are represented in your application by stand-in objects called faults to make retrieval of the actual objects easier.
Without uniquing, you'd get a new enterprise object every time you fetch its corresponding row, whether explicitly or through resolution of relationships. This is illustrated in Figure 49.
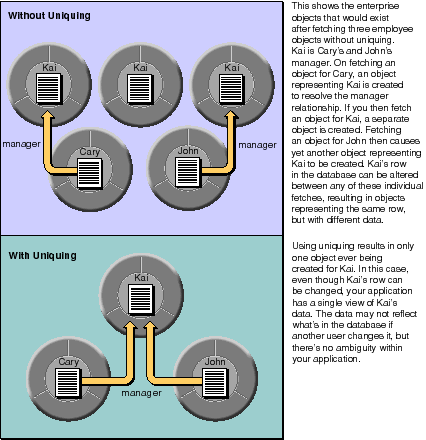
Figure 49. Uniquing of Enterprise Objects
Uniquing occurs in the control layer, and it's based on an object's globalID. A globalID consists of an object's primary key and its associated entity. When a row is fetched to create an object in a particular EOEditingContext, its globalID is checked against the objects already in the EOEditingContext. If a match is found, the newly fetched object isn't added to the context.
A single enterprise object instance exists in one and only one EOEditingContext, but multiple copies of an object can exist in different editing contexts. In other words, object uniquing is scoped to a particular editing context.
A snapshot is a dictionary object recording a row's primary key, class properties, foreign keys for class property relationships, and the attributes of that object that are used for locking during an update. (Primary keys and attributes used for locking are defined in a model; see the book Enterprise Objects Framework Tools and Techniques.) A snapshot is recorded under the globalID of its enterprise object whenever the object is fetched or modified.
When changes to an object are saved to the database, the snapshot is compared with the corresponding database row to ensure that the row data hasn't changed since the object was last fetched. For a discussion of how this relates to the update strategy you set for your application, see the section "Locking and Update Strategies".
When the database level fetches an object, it examines the relationships defined in the model and creates objects representing the destinations of the fetched object's relationships. For example, if you fetch an employee object, you can ask for its manager and immediately receive an object; you don't have to get the manager's employee ID from the object you just fetched and fetch the manager yourself.
The database level doesn't immediately fetch data for the destination objects of relationships, however. Fetching is fairly expensive, and further, if the database level fetched objects related to the one explicitly asked for, it would also have to fetch the objects related to those, and so on, until all of the interrelated rows in the database had been retrieved. To avoid this waste of time and resources, the destination objects created are stand-ins, or faults.
Faults come in two varieties: single-object faults for to-one relationships, and array faults for to-many relationships. In Java, a single-object fault is merely a partially initialized enterprise object. It's been created with a constructor of the form:
public MyCustomEO (and so is already associated with a particular editing context, a class description, and a globalID. However, the object's data hasn't yet been fetched from the database. This part of the object's initialization is delayed until the object receives a message which requires it to fetch its data.
EOEditingContext anEOEditingContext,
EOClassDescription anEOClassDescription,
EOGlobalID anEOGlobalID)
In Objective-C on the other hand, single-object faults are objects of a special class (EOFault) whose instances transform themselves into actual enterprise objects-and fetch their data-the first time they're accessed. These Objective-C faults occupies the same amount of memory as an instance of the target class (into which it's eventually transformed), and stores the information needed to retrieve the data associated with the fault (the source globalID and relationship name). A fault object thus consumes about as much memory as an empty instance of its target class.
An Objective-C fault behaves in every way possible as an instance of its target class until it receives a message it can't cover for. For example, if you fetch an Employee object and ask for its manager, you get a fault object representing another Employee object. If you send a class message to this fault object, it returns the Employee class. If you send the fault object a message requesting the value of an attribute, such as lastName, however, it uses the EODatabaseContext that created it to retrieve its data from the database, overwrites its class identity, and invokes the target class's implementation of lastName.
Figure 50 illustrates this process.
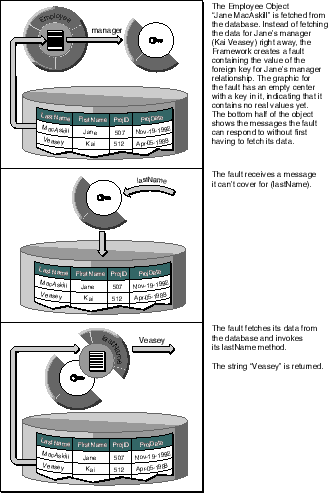
Figure 50. Resolution of a Fault Object
Array faults are treated similarly by both languages. They behave as instances of the NSMutableArray class, and are triggered to fetch their objects by any request for a member object or for the number of objects in the array (the number of objects for a to-many relationship can't be determined without actually fetching them all).
For more information on faults, see the EOFaulting interface specification (Java only), the EOFault class specification (Objective-C only), and the EOFaultHandler class specification (or both languages) in the Enterprise Objects Framework Reference.
When an EODatabaseChannel constructs a fault for a to-one relationship, it checks the globalID for the destination to see whether that object already exists in the EOEditingContext. If so, it simply uses that object to immediately resolve the relationship. This preserves the uniqueness requirement for enterprise objects, in that there's never more than one globalID representing the same row in the database. Whether that globalID represents an actual enterprise object or a fault doesn't matter, since the data will be fetched when it's needed.
Similarly, if an EODatabaseChannel fetches data for an object that's already been created as a fault, the EODatabaseChannel fires the fault. In Java, this simply means that it finishes initializing the object with the data it's fetched. In Objective-C, this means that the database channel turns the fault into an instance of its target class, without changing its id, and then initializes the resulting enterprise object. In either case, the process is essentially the same whether you fetch the fault's data or whether the fault fetches the data itself upon being sent a message.
Table of Contents  Next Section
Next Section